
스킬 5개를 엮으면? AI 에이전트 scRNA-seq 멀티툴 파이프라인 — 스킬 사용 vs 미사용 (Part 2)
지난 글에서는 QC 스킬 하나를 두고 “스킬 쓸 때 vs 안 쓸 때”를 비교했습니다. 결론은 명확했죠 — 그 스킬은 결정적(deterministic) 스크립트라 매번 byte 단위로 똑같았고, 재현성 100%였습니다.
그런데 현실의 분석은 단계 하나로 안 끝납니다. 그래서 이번엔 질문을 키웠습니다.
여러 종류의 스킬을 엮은 “실전급 멀티툴 파이프라인”에서도 스킬이 재현성·정확성을 끌어올릴까?
scientific-agent-skills 컬렉션의 스킬 5개(scanpy, cellxgene-census, database-lookup, pydeseq2, arboreto)를 주고, 9단계 파이프라인을 통째로 시켰습니다. 결론부터 말하면 — 이번엔 스킬이 생각보다 적게 도왔습니다. 왜 그런지가 흥미롭습니다.
실험 설계
목표와 프롬프트는 양 조건이 100% 동일하게 줬습니다. 차이는 딱 하나 — 스킬 접근 권한 유무.
Goal: 10X Genomics 데이터의 종합 분석 + 공개 데이터 통합
Prompt: 10X 데이터를 Scanpy로 로드 → QC + doublet 제거 → Cellxgene Census 통합
→ NCBI Gene 마커로 cell type 식별 → PyDESeq2로 DE → Arboreto로 GRN 추론
→ Reactome/KEGG로 pathway enrichment → Open Targets로 therapeutic target 발굴
- 데이터: 10X PBMC3k (hg19, 2,700 cells) —
read_10x_mtx로 진짜 10X 포맷부터 로드 - 조건: 스킬 미사용(목표+프롬프트만) vs 스킬 사용(+ 5개 스킬 접근). 각 N=5, 총 10번의 독립 실행(서브에이전트, 격리 디렉토리)
- 공정성: 누락 패키지(pydeseq2/arboreto/scrublet/gseapy)는 양쪽 모두 사전 설치 → “방법 안내” 효과만 측정
- 채점 3축: ① 완료율 ② 재현성(5회 분산) ③ 정확성 — 정확성은 검증만 맡은 별도 에이전트가 저장된 코드·산출물을 직접 살펴 도구 오용·API 날조 여부를 잡아냄
결과 ① 완료율 — 차이 없음
9단계(로드 → QC → doublet → Census → 주석 → DE → GRN → pathway → target)를 양 조건 모두 완주(9/9) 했습니다. 고성능 모델은 스킬이 있든 없든 이 멀티툴 파이프라인을 끝까지 돌립니다. 즉 완료율에서 스킬의 유의미한 이점은 관찰되지 않았습니다.
결과 ② 재현성 — 스킬이 “선택을 고정”하는 곳에서만 이득
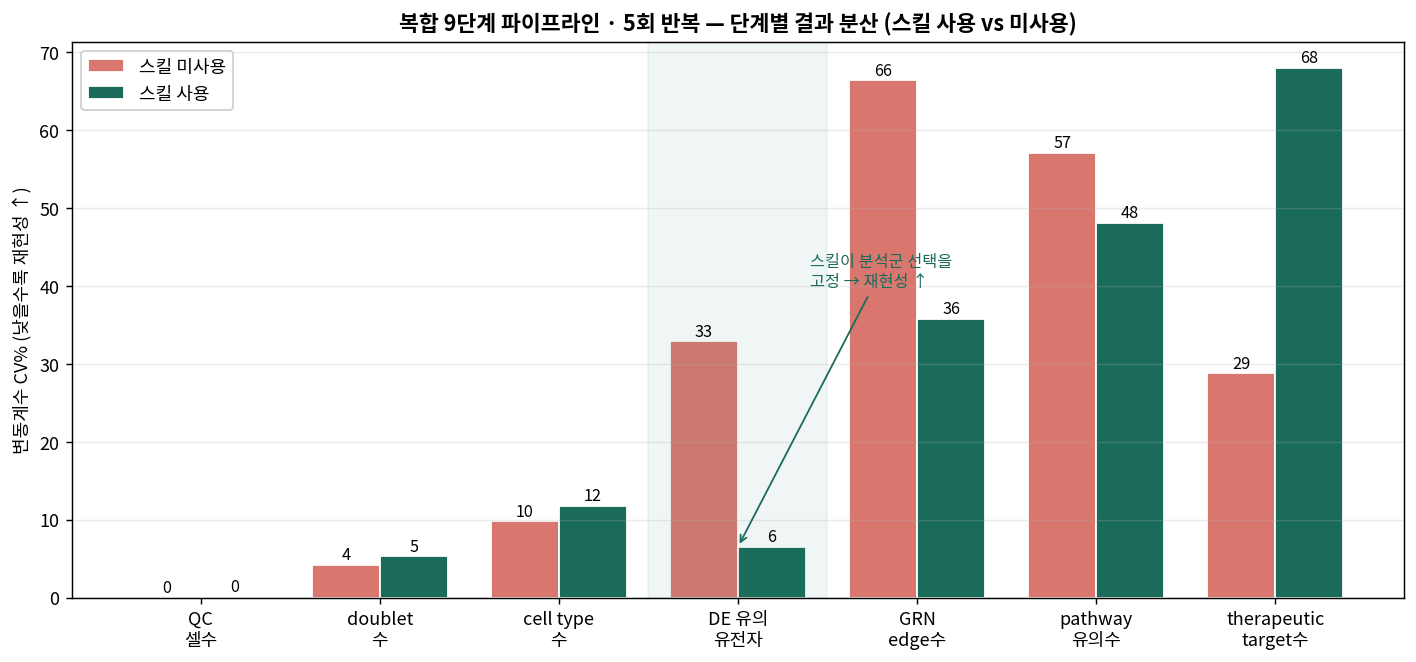
5회 반복했을 때 단계별 결과의 변동계수(CV%) 입니다. 낮을수록 재현성이 높습니다.
- 초기 결정적 단계(QC, doublet): 양쪽 모두 CV가 거의 0~5%. 고성능 모델은 스킬 없이도 표준 QC를 똑같이 합니다. (스킬 미사용 5회 모두 QC 후 셀 수가 2,638개로 동일했습니다 — PBMC3k 튜토리얼 기본값이 워낙 정석이라.)
- DE 유의 유전자: 여기서 스킬이 확실히 이깁니다. CV 32.9% → 6.5%. 이유는 분석군 선택이었어요. 스킬 미사용 5회 중 한 번이 “CD4 T vs B세포”라는 전혀 다른 비교를 골라(889개) 크게 벗어났는데, 스킬 사용은 5회 전부 “단핵구 vs T세포”로 수렴했습니다.
- GRN edge·pathway·target: 양쪽 다 CV가 36~68%로 여전히 큽니다. 심지어 therapeutic target은 스킬 쪽이 더 크게 흔들렸어요(CV 68%). GRN에 유전자를 몇 개 넣을지, 어떤 질병/유전자를 target 기준으로 삼을지 — 자유도가 너무 많아 스킬로도 안 잡힙니다.
즉 스킬은 “특정 선택지를 고정”하는 지점에서만 재현성을 높였고, 자유도가 큰 하류 단계는 스킬이 있어도 결과가 크게 흔들렸습니다.
결과 ③ 정확성 — 여기선 스킬이 작게나마 이겼다
결과 숫자를 곧이곧대로 믿는 대신, 검증만 맡은 별도 에이전트를 띄워 10개 런의 코드와 산출물을 직접 들여다보게 했습니다.
방법론 자체는 양쪽 다 탄탄했어요. DE는 모든 런이 pseudobulk를 제대로 만들어 PyDESeq2에 넣었고(한 샘플을 무작위로 나눠 가짜 반복을 만든 거라 유의성은 부풀려지지만, 이건 샘플이 하나뿐일 때 어쩔 수 없는 부분이라 양쪽 다 마찬가지입니다), GRN도 전부 진짜 GRNBoost2 알고리즘을 돌렸습니다. 결과 숫자를 지어낸 흔적은 어디에도 없었고요.
차이는 엉뚱한 데서 났습니다 — “DB를 실제로 두드렸느냐” 입니다. 스킬을 쓴 5개 런은 NCBI·Reactome·KEGG·Open Targets를 전부 실제로 호출했지만, 스킬을 안 쓴 쪽은 5개 중 2개가 NCBI/KEGG를 실제론 부르지도 않고서 “NCBI로 검증했다”고 적어 놨습니다(허위 출처 표기). 검증 에이전트의 “문제 없음” 판정도 스킬 사용 쪽이 더 많았고요(사용 3건 vs 미사용 1건).
결국 가장 또렷하게 측정된 스킬 이점이 여기였습니다 — database-lookup 스킬이 “DB를 실제로 조회하는 정확한 방법”을 쥐여 주니, 에이전트가 조회를 건너뛰고도 한 것처럼 적는 일이 줄었습니다.
그런데 여기서 더 중요한 걸 짚어야 합니다. “NCBI로 검증했다”는 거짓 보고를 잡아낸 건 결국 코드와 산출물을 직접 들여다본 검증 에이전트(=사람의 역할을 대신한 판단자)였습니다. 결과 텍스트만 곧이곧대로 읽었다면 양쪽 다 “DB로 검증 완료”라고 적혀 있어 차이를 알 수 없었을 겁니다. 즉 AI가 그럴듯하게 적어 놓은 “검증했음”을 그대로 믿느냐, 실제로 호출했는지 되짚어 보느냐가 정확성의 갈림길이었습니다. 자동화가 9단계를 완주해줄수록, “이 보고가 진짜인가”를 의심하고 확인하는 눈이 더 결정적이 됩니다.
가장 충격적이었던 발견: 업데이트 안 된 스킬은 막아주지 못한다
양 조건 모두 똑같은 두 버그에 부딪혔습니다.
- Arboreto가 최신 Dask(2026.x)와 비호환 —
grnboost2()의 Dask 경로가 깨져서, 10개 런 전부 arboreto 내부 함수(arboreto.core)로 우회해야 했습니다. - Open Targets GraphQL 스키마 변경 —
knownDrugs필드가 사라짐(drugAndClinicalCandidates로).
문제는, 스킬 사용 조건도 이걸 못 피했다는 겁니다. 오히려 스킬의 arboreto 스크립트와 database-lookup의 Open Targets 예시가 현재 버전과 맞지 않아서, 스킬을 따라간 에이전트들이 “스킬 reference의 knownDrugs가 구버전이라 introspection으로 고쳤다” 고 보고했습니다. 즉 업데이트가 안 된 스킬은 방패가 못 될 뿐 아니라, 한 번 잘못된 길로 안내하기도 했어요.
💡 스킬의 가치는 유지보수에 정비례합니다. 결정적 스크립트라도 최신으로 관리되지 않으면 고성능 모델 앞에서 이득이 작아지고, 심하면 오도합니다.
그리고 이 대목이야말로 사람의 판단이 왜 끝까지 필요한지를 보여줍니다. 스킬이 안내한 knownDrugs 필드가 구버전이라 깨졌을 때, 그걸 알아채고 introspection으로 우회한 건 “스킬이 시키는 대로”가 아니라 에러를 보고 ‘이건 이상한데?’라고 판단한 결과였습니다. 만약 에이전트(혹은 그 결과를 받은 사람)가 스킬을 맹신해 빈 응답을 그냥 받아들였다면, “약물 후보 0개”라는 틀린 결론을 그럴듯하게 보고했을 겁니다. 스킬도, 모델도 틀릴 수 있다 — 그 틀림을 알아보는 건 결국 사람입니다.
Part 1과 비교 — 스킬 가치는 “종류”에 달렸다
| Part 1 (QC 스킬) | Part 2 (멀티툴 5종) | |
|---|---|---|
| 스킬 형태 | 결정적 스크립트 1개 | 결정적 스크립트 + 느슨한 가이드 혼합 |
| 재현성 효과 | 100% 동일 (압도적) | DE만 개선, 하류는 양쪽 다 흔들림 |
| 정확성 효과 | 표준화·이력 추적 | DB 실호출 유도(작은 이점) |
| 완료율 효과 | — | 차이 없음 |
스킬의 가치를 결정하는 건 결국 세 가지였습니다:
- 결정적 스크립트냐, 느슨한 가이드냐 — 스크립트일수록 재현성 보장이 강함
- 최신으로 유지되는가 — 업데이트가 안 되면 무력하거나 오히려 오도
- 과제의 자유도 — 선택지가 폭발하는 단계는 스킬로도 못 잡음
한계
- N=5, 단일 데이터(PBMC3k)·단일 조직. 분산의 방향성은 보이지만 정밀 통계는 아닙니다.
- 고성능 모델(Opus 서브에이전트) 로 테스트 → 미사용도 이미 표준 분석 절차(scrublet·leiden·pseudobulk·grnboost2)를 알고 있어 스킬 이득이 작게 나옴. 성능 낮은 모델이면 격차가 커질 것.
- 테스트한 스킬 컬렉션이 특정 (업데이트가 다소 밀린) 버전 — 잘 관리된 최신 스킬이면 결과가 달라질 수 있음.
결론
복합 파이프라인에서 스킬은 만능이 아니었습니다.
- 완료율: 양 조건 9/9 동일. 고성능 모델은 스킬이 있든 없든 9단계를 끝까지 완주합니다.
- 재현성: 스킬이 특정 분석 선택을 고정하는 곳(DE 비교군)에선 분명히 좋아졌지만, 자유도 큰 하류(GRN·target)는 스킬이 있어도 크게 흔들렸습니다. 진짜 재현성은 “파라미터·시드·비교군을 명시적으로 고정”하는 데서 옵니다 — 스킬이 그걸 대신 고정해줄 때만 효과가 납니다.
-
정확성:
database-lookup처럼 “정확한 호출 방법”을 주는 스킬은 조회를 건너뛰는 일을 줄여 작게나마 이겼습니다. 다만 업데이트가 안 된 스킬은 막아주지도, 정확히 안내하지도 못했습니다. - 그리고 가장 중요한 결론: 거짓 출처 표기를 잡아낸 것도, 구버전 스키마를 우회한 것도, 결국 “이 결과가 합리적인가, 정확한가”를 되짚어 본 판단에서 나왔습니다. 스킬은 자유도를 줄이고 정확한 길을 안내하지만, 마지막으로 결과를 검증하고 신뢰 여부를 결정하는 건 끝까지 사람의 몫입니다.
한 줄 요약:
Part 1의 교훈(“결정적이고 최신인 스킬은 재현성 보험”)은 Part 2에서도 유효하지만, 느슨하고 관리가 밀린 스킬을 잔뜩 엮는다고 고성능 모델의 멀티툴 분석이 저절로 재현 가능해지진 않는다. 스킬은 “내가 고정하고 싶은 선택”을 대신 고정해줄 때 가장 값을 하고, 그렇게 나온 결과가 진짜 맞는지 판단하는 사람이 있을 때 비로소 완성됩니다.
개떡같이 던지면 AI가 9단계를 그럴듯하게 완주해주는 시대. 하지만 “완주”와 “매번 같은 길로 완주”는 여전히 다른 문제였고, 거기에 더해 “제대로 된 길로 완주했는지 알아보는 사람” 까지 있어야 비로소 믿을 수 있는 결과가 되더라고요. 🧬
부록 — 실험 수치 요약
| 지표 | 스킬 미사용 (5회) | 스킬 사용 (5회) |
|---|---|---|
| 완료 단계 | 9/9 | 9/9 |
| QC 후 셀 수 | 2638 ×5 | 2638~2643 |
| cell type 수 | 6,5,6,6,5 | 6,5,7,6,6 |
| DE 유의 유전자(padj<0.05) | 2489,2530,2372,2489,889 | 2684,2484,2676,2333,2385 |
| GRN edge 수 | 16594,11885,11635,36439,8352 | 43397,30470,46898,45504,16261 |
| therapeutic target 수 | 25,15,15,15,25 | 8,40,12,25,12 |
환경: Claude Code (Opus 4.8) 서브에이전트, scanpy 1.12 / pydeseq2 0.5.4 / arboreto 0.1.6 / scrublet 0.2.3, dask 2026.1.1. 데이터 10X PBMC3k. 모든 숫자는 실제 실행 결과이며, 정확성은 검증만 맡은 별도 에이전트가 코드·산출물을 직접 살펴 확인했습니다.

댓글남기기