
Hail - (1) Hail이란?
1. Hail의 등장 배경
Hail에 대해서는 아직 우리나라에서는 생소한 패키지일 수도 있습니다. 하지만 Next Generation Sequencing의 등장으로 Whole Genome Sequencing과 같이 규모가 큰 Genomics Data의 생산이 가능해지고 이를 Cluster 또는 Cloud를 이용하여 빠르게 처리할 필요가 생기면서 탄생한 패키지라고 보시면 됩니다. MIT에서 만들었고 Spark를 기반으로 하며 Python API를 제공하는 오픈 소스 라이브러리입니다.
Hail의 장점은 확장성(Scalability)과 효율성(Efficiency)입니다. 하나의 컴퓨터로는 막대한 크기의 데이터를 다루기 힘든 상황에서 Hail은 여러 대의 컴퓨터를 동시에 사용하여 데이터를 병렬적으로 처리할 수 있게 해줍니다.
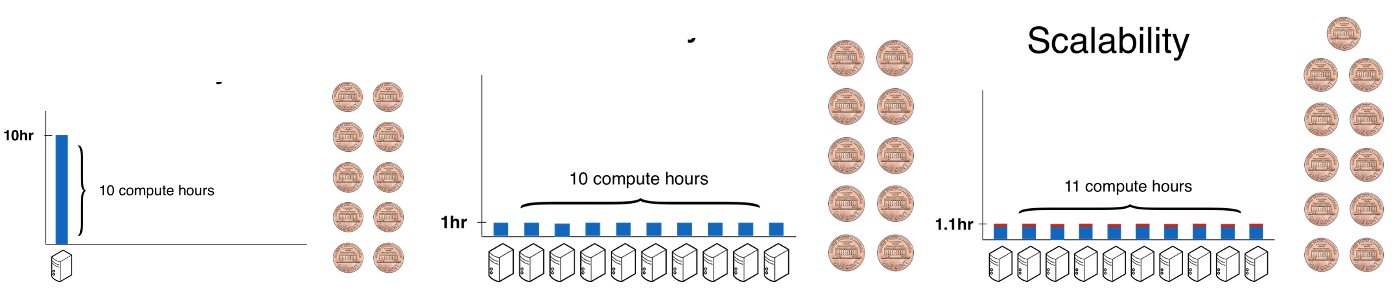
< Scalability of Hail >
Hail을 통해서 할 수 있는 작업은 여러가지가 있지만 대표적인 몇가지를 소개하면 다음과 같습니다.
- Sample or Variant-level QC
- Variant Annotation
- Identity by Descent (IBD)
- Principal Component Analysis (PCA) …
그 외에도 간단한 시각화, Regression 등 Hail의 용도는 매우 다양합니다. 각각의 작업에 대해서는 나중에 하나씩 다뤄보겠습니다.
2. Matrix Table이란?
Hail의 간판이라고 할 수 있는 특별하고 중요한 구성요소인 Matrix Table에 대해서 알아보겠습니다. Matrix Table은 Hail에서 자체적으로 개발한 Genomic Dataframe입니다. VCF, BGEN, PLINK 등 여러 파일 형식을 Matrix Table로 변환하여 처리를 합니다. Matrix Table은 Global, Row, Column, Entry fields 크게 4가지 부분으로 나눌 수 있는데, Global fields는 전반적인 Table의 메타데이터, Row fields는 주로 variant에 대한 정보, Column fields는 sample에 대한 정보, 마지막으로 Entry fields는 Row, Columm에 대한 2차원 구조 Matrix의 element로 주로 Genotype 정보를 담고 있습니다. 다음 그림을 보시면 더 이해가 쉬우실 것입니다.
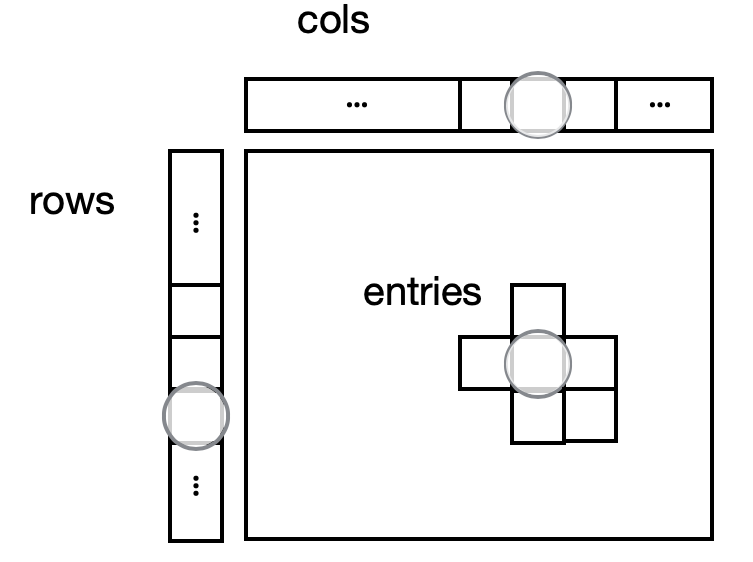
< Anatomy of the MatrixTable >
예를 들어, Sample의 성별 정보는 Column field, Variant의 Allele Frequency 정보는 Row field, Sample의 Variant Call 정보는 Entry field로 저장됩니다. 나중에도 다룰 내용이지만 Hail은 Spark를 기반으로 하기 때문에 Matrix Table이 분산된 형태(Distributed)로 존재하여 CPU의 여러 개의 core가 병렬적으로 데이터를 처리할 수 있습니다. key라는 요소에 의해 index되어 있다는 것도 특징입니다.
Hail이 무슨 물건인지 알아보았으니 이제 본격적으로 Hail 설치부터 시작해서 Hail을 이모저모로 뜯어보기로 할까요.


댓글남기기